kubeadm安装高可用k8s集群
0 k8s高可用架构
在介绍部署方式前,先介绍一下k8s的高可用架构。
0.1 与keepalive+VIP对比
网上大量的人使用KeepAlive+VIP的形式完成高可用,这个方式有两个不好的地方:
其一,受限于使用者的网络,无法适用于SDN网络,比如Aliyun的VPC。
其二,虽然是高可用的,但是流量还是单点的,所有node的的网络I/O都会高度集中于一台机器上(VIP),一旦集群节点增多,pod增多,单机的网络I/O迟早是网络隐患。
0.2 两种模式
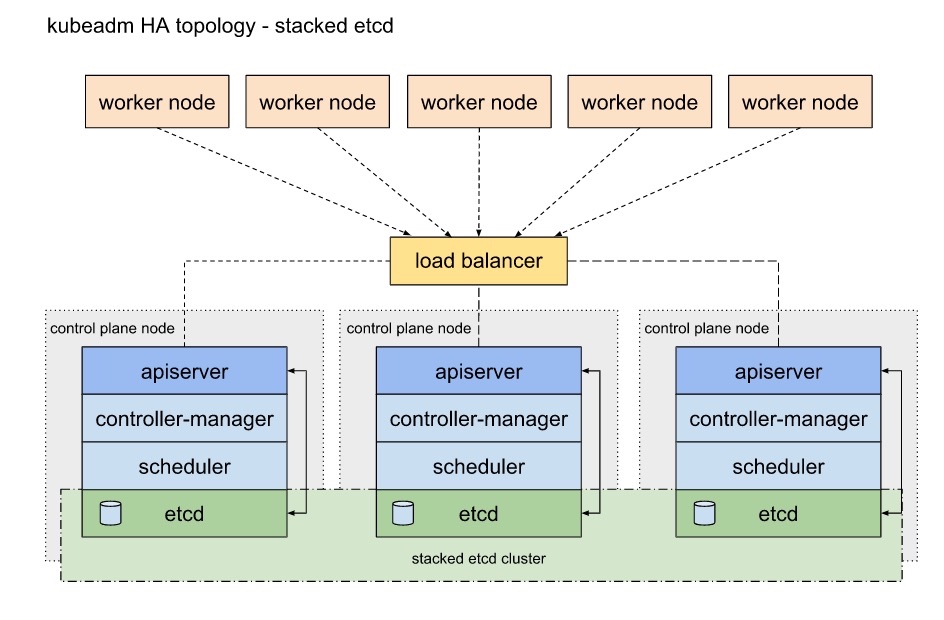
0.2.1 堆叠式etcd拓扑
堆叠式拓扑的意思是存储元数据的etcd与控制屏幕节点安装在同一台服务器上,共同被kubeadm所管理。
每个控制平面节点都运行一组kube-apiserver,kube-scheduler和kube-controller-manager,其中kube-apiserver通过负载均衡暴露给所有worker节点。
每个控制平面节点都创建一个本地etcd,这个本地etcd只与该控制平面节点的kube-apiserver通讯,kube-scheduler和kube-controller-manager也是节点独立的。
介绍一下这种方案的优缺点: 优点:这种控制平面和etcd部署在同一个节点的模式比控制平面和etcd分离部署安装容易并且易于管理副本。 缺点:这种模式存在错误耦合的缺点,当一个节点宕机,etcd和控制平面实例都丢失,只能添加更多的控制平面节点来缓和这个问题。
在高可用集群下需要运行至少3个堆叠控制平面节点。
这是kubeadm高可用的默认实现方案,运行kubeadm init和kubeadm join –control-plane后本地etcd将被自动创建。
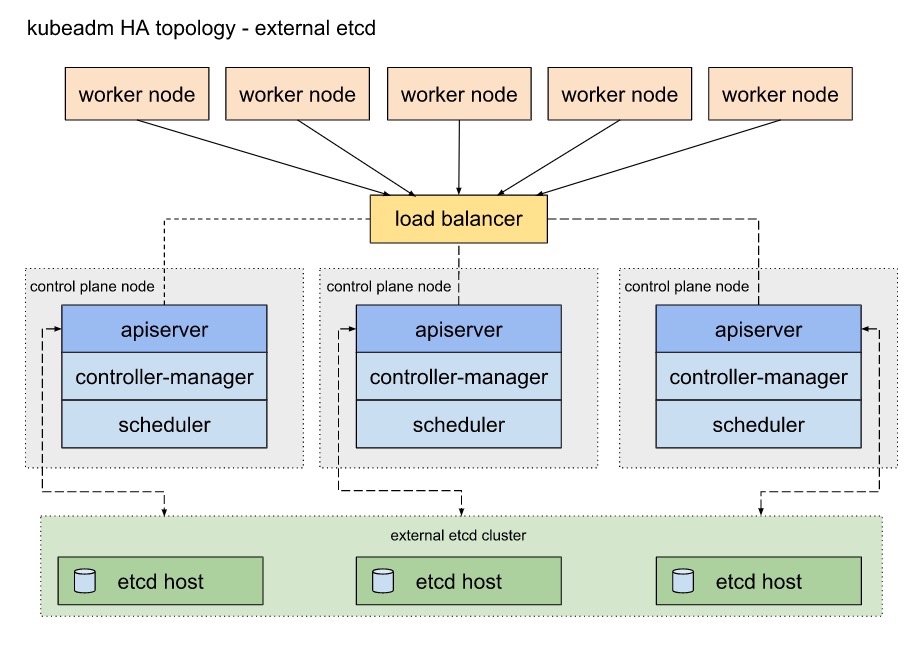
0.2.2 分离式etcd拓扑
分离式拓扑的意思是存储元数据的etcd与控制屏幕节点安装在不同服务器上。
类似于堆叠式架构,每个控制平面节点都运行一组kube-apiserver,kube-scheduler和kube-controller-manager,其中kube-apiserver通过负载均衡暴露给所有worker节点。不同的地方在于,etcd在不同的host上运行,每个etcd都会和每个控制平面上的kube-apiserver交互。
这种拓扑结构将etcd与控制平面进行了分离。这种方式与堆叠式架构相比可以在etcd的节点丢失以及控制平面的节点丢失上有更高的容错性。
然而,这种拓扑结构在机器数量上对比堆叠式架构需要两倍的数量。需要至少3个etcd节点以及3个控制平面节点。
1 前置安装
1.1 环境相关
安装docker和kubeadm,在每一台机器上都需要安装。
1:ssh可信
2:hosts
cat>>/etc/hosts<<EOF
10.57.26.15 k8s-01
10.57.26.7 k8s-02
10.57.26.8 k8s-03
10.57.26.26 k8s-04
10.57.26.11 k8s-05
10.57.26.17 k8s-06
10.57.26.33 k8s-07
EOF
host名需要和 hostname /etc/hostname 一致
3:安全相关
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
systemctl disable firewalld.service
systemctl stop firewalld.service
systemctl disable iptables.service
systemctl stop iptables.service
4:源和代理
echo proxy=http://10.57.22.8:3128/ >> /etc/yum.conf
cat>/etc/yum.repos.d/docker-ce.repo<<EOF
[docker-ce-stable]
name=Docker CE Stable - $basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/$basearch/stable
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
EOF
cat>/etc/yum.repos.d/kubernetes.repo<<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
5:安装docker和kubeadm
yum install -y docker
yum install -y kubeadm
systemctl start docker
systemctl enable docker
systemctl enable kubelet
echo KUBELET_EXTRA_ARGS="\"--fail-swap-on=false\"" > /etc/sysconfig/kubelet
systemctl daemon-reload&&systemctl restart kubelet
6:私有仓库以及网络
cat>/etc/sysctl.conf<<EOF
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl -p
cat>/etc/docker/daemon.json<<EOF
{
"registry-mirrors": ["https://a5aghnme.mirror.aliyuncs.com"],
"insecure-registries":["10.57.26.15:4000"]
}
EOF
systemctl daemon-reload
systemctl restart docker
1.2 私有仓库搭建
需要选取一台服务器来安装私仓,因为只是私用,所以只安装最简单的registry,在这里不安装harbor。
1.2.1 设置代理
#create older
mkdir -p /etc/systemd/system/docker.service.d
#add http-proxy.conf
cat>/etc/systemd/system/docker.service.d/http-proxy.conf<<EOF
[Service]
Environment="HTTP_PROXY=http://10.57.22.8:3128/"
EOF
systemctl daemon-reload
systemctl restart docker
设置成功后,执行docker search 镜像。就可以看到可以下载的镜像。
1.2.2 私仓安装
执行
# 下载镜像
docker pull registry:2
# 运行私仓镜像,暴露4000端口
docker run -d -v /opt/registry:/var/lib/registry -p 4000:5000 --restart=always --name registry registry:2
# 在确定selinux关闭后,将已备份的镜像拷贝至/opt/registry目录下。
# 查看私仓镜像
curl -XGET http://10.57.26.15:4000/v2/_catalog
1.3 创建Kube-apiserver的负载均衡
- 通过创建DNS名来创建kube-apiserver的负载均衡器。 1) 需要将控制平面节点放置于负责TCP转发的负载均衡器后面。这个负载均衡器会将流量分布到所有配置的控制平面上。kube-apiserver的健康检测的端口是kube-apiserver的启动端口,默认是6443 2) 建议控制平面使用域名。 3) 负载均衡需要能访问所有配置的控制平面域名,ip和端口。 4) 可以使用nginx和haproxy等作为负载均衡器实现。 5) kubeadm中的ControlPlaneEndpoint需要设置成负载均衡器的地址。
- 添加第所有控制平面节点到负载均衡中。 使用Nginx-Poxy来作为负载均衡器,配置nginxProxy,kube-servers处写上需要代理的多个kube-apiserver的地址
mkdir -p /etc/nginx
cat > /etc/nginx/nginx.conf << EOF
worker_processes auto;
user root;
events {
worker_connections 20240;
use epoll;
}
error_log /var/log/nginx_error.log info;
stream {
upstream kube-servers {
hash $remote_addr consistent;
server server1.k8s.local:6443 weight=5 max_fails=1 fail_timeout=10s;
server server2.k8s.local:6443 weight=5 max_fails=1 fail_timeout=10s;
server server3.k8s.local:6443 weight=5 max_fails=1 fail_timeout=10s;
}
server {
listen 8443;
proxy_connect_timeout 1s;
proxy_timeout 3s;
proxy_pass kube-servers;
}
}
EOF
配置文件写好后,加载ipvs模块,并运行nginxproxy
# 加载模块 <module_name>
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
# 检查加载的模块
lsmod | grep -e ipvs -e nf_conntrack_ipv4
docker run --restart=always \
-v /etc/nginx/nginx.conf:/etc/nginx/nginx.conf \
--name kube_server_proxy \
--net host \
-it \
-d \
nginx
1.4 镜像拉取
export REGISTRY_HOST=10.57.26.7:4000
curl -XGET http://${REGISTRY_HOST}/v2/_catalog
docker pull ${REGISTRY_HOST}/kube-proxy:v1.15.0
docker pull ${REGISTRY_HOST}/kube-apiserver:v1.15.0
docker pull ${REGISTRY_HOST}/kube-controller-manager:v1.15.0
docker pull ${REGISTRY_HOST}/kube-scheduler:v1.15.0
docker pull ${REGISTRY_HOST}/coredns:1.3.1
docker pull ${REGISTRY_HOST}/etcd:3.3.10
docker pull ${REGISTRY_HOST}/pause:3.1
docker tag ${REGISTRY_HOST}/kube-proxy:v1.15.0 k8s.gcr.io/kube-proxy:v1.15.0
docker tag ${REGISTRY_HOST}/kube-apiserver:v1.15.0 k8s.gcr.io/kube-apiserver:v1.15.0
docker tag ${REGISTRY_HOST}/kube-controller-manager:v1.15.0 k8s.gcr.io/kube-controller-manager:v1.15.0
docker tag ${REGISTRY_HOST}/kube-scheduler:v1.15.0 k8s.gcr.io/kube-scheduler:v1.15.0
docker tag ${REGISTRY_HOST}/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1
docker tag ${REGISTRY_HOST}/etcd:3.3.10 k8s.gcr.io/etcd:3.3.10
docker tag ${REGISTRY_HOST}/pause:3.1 k8s.gcr.io/pause:3.1
2 堆叠模式安装
堆叠模式安装比较简单,至少需要3台机器,安装etcd和控制平面。
2.1 第一个控制平面安装
编写配置文件如下
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
apiServer:
certSANs:
- "10.57.26.15"
controlPlaneEndpoint: "k8s-01:8443"
networking:
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
1)运行
kubeadm init --config kubeadm-config.yaml --upload-certs
2) 记录下join命令。
3)安装网络插件,这里使用flannel。
2.2 其他控制平面安装
1)保证第一个控制平面安装成功。
2)加入第一个控制平面安装成功输出的加入控制平面的命令,需要立即输入,key过2小时就将过期。
2.3 worker节点安装
1)保证控制节点安装成功。
2)加入第一个控制平面安装成功输出的加入工作节点的命令。
3 分离模式安装
分离模式至少需要6台机器,3台安装etcd,3台安装控制平面。
3.1 etcd集群安装
3.1.1 配置kubelet成为etcd的服务管理
设置后可以覆盖老的kubeadm的启动方式
mkdir -p /etc/systemd/system/kubelet.service.d/
cat << EOF > /etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf
[Service]
ExecStart=
ExecStart=/usr/bin/kubelet --address=127.0.0.1 --pod-manifest-path=/etc/kubernetes/manifests
Restart=always
EOF
systemctl daemon-reload
systemctl restart kubelet
3.1.2 创建etcd集群配置文件
#清理,如果不清理会识别老的member信息导致后续通讯失败
rm -rf /var/lib/etcd/*
# Update HOST0, HOST1, and HOST2 with the IPs or resolvable names of your hosts
export HOST0=10.57.26.7
export HOST1=10.57.26.8
export HOST2=10.57.26.26
# Create temp directories to store files that will end up on other hosts.
mkdir -p /tmp/${HOST0}/ /tmp/${HOST1}/ /tmp/${HOST2}/
ETCDHOSTS=(${HOST0} ${HOST1} ${HOST2})
NAMES=("k8s-02" "k8s-03" "k8s-04")
for i in "${!ETCDHOSTS[@]}"; do
HOST=${ETCDHOSTS[$i]}
NAME=${NAMES[$i]}
cat << EOF > /tmp/${HOST}/kubeadmcfg.yaml
apiVersion: "kubeadm.k8s.io/v1beta2"
kind: ClusterConfiguration
etcd:
local:
serverCertSANs:
- "${HOST}"
peerCertSANs:
- "${HOST}"
extraArgs:
initial-cluster: ${NAMES[0]}=https://${ETCDHOSTS[0]}:2380,${NAMES[1]}=https://${ETCDHOSTS[1]}:2380,${NAMES[2]}=https://${ETCDHOSTS[2]}:2380
initial-cluster-state: new
name: ${NAME}
listen-peer-urls: https://${HOST}:2380
listen-client-urls: https://${HOST}:2379
advertise-client-urls: https://${HOST}:2379
initial-advertise-peer-urls: https://${HOST}:2380
EOF
done
3.1.3 生成ca
etcd节点中有一台存储ca。如果不存在ca的话生成方法: kubeadm init phase certs etcd-ca 如果/etc/kubernetes/pki/etcd/ca.crt 和 /etc/kubernetes/pki/etcd/ca.key存在可进入下一步
3.1.4 为每个etcd member创建配置
kubeadm init phase certs etcd-server --config=/tmp/${HOST2}/kubeadmcfg.yaml
kubeadm init phase certs etcd-peer --config=/tmp/${HOST2}/kubeadmcfg.yaml
kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST2}/kubeadmcfg.yaml
kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST2}/kubeadmcfg.yaml
cp -R /etc/kubernetes/pki /tmp/${HOST2}/
# cleanup non-reusable certificates
find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete
kubeadm init phase certs etcd-server --config=/tmp/${HOST1}/kubeadmcfg.yaml
kubeadm init phase certs etcd-peer --config=/tmp/${HOST1}/kubeadmcfg.yaml
kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST1}/kubeadmcfg.yaml
kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST1}/kubeadmcfg.yaml
cp -R /etc/kubernetes/pki /tmp/${HOST1}/
find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete
kubeadm init phase certs etcd-server --config=/tmp/${HOST0}/kubeadmcfg.yaml
kubeadm init phase certs etcd-peer --config=/tmp/${HOST0}/kubeadmcfg.yaml
kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST0}/kubeadmcfg.yaml
kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST0}/kubeadmcfg.yaml
# No need to move the certs because they are for HOST0
# clean up certs that should not be copied off this host
find /tmp/${HOST2} -name ca.key -type f -delete
find /tmp/${HOST1} -name ca.key -type f -delete
3.1.5 拷贝到目录
ca上运行拷贝
scp -r /tmp/${HOST1}/* root@${HOST1}:
scp -r /tmp/${HOST2}/* root@${HOST2}:
然后进入每个member中,执行
mv pki /etc/kubernetes/
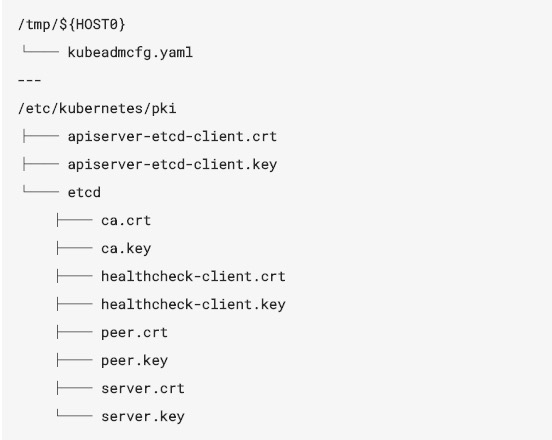
3.1.6 拷贝后的文件结构
含有ca的etcd节点文件结构:
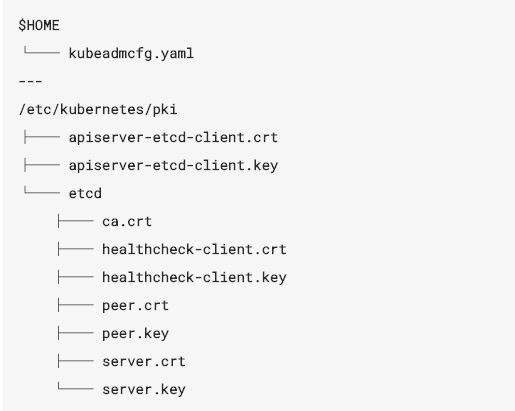
其他member的节点文件结构:
3.1.7 创建静态pod manifest,并启动
执行后可以看到docker ps中有etcd进程。可见etcd已经被容器化了。
root@HOST0 $ kubeadm init phase etcd local --config=/tmp/${HOST0}/kubeadmcfg.yaml
root@HOST1 $ kubeadm init phase etcd local --config=kubeadmcfg.yaml
root@HOST2 $ kubeadm init phase etcd local --config=kubeadmcfg.yaml
3.1.8 检测etcd状态
docker run --rm -it \
--net host \
-v /etc/kubernetes:/etc/kubernetes quay.io/coreos/etcd:${ETCD_TAG} etcdctl \
--cert-file /etc/kubernetes/pki/etcd/peer.crt \
--key-file /etc/kubernetes/pki/etcd/peer.key \
--ca-file /etc/kubernetes/pki/etcd/ca.crt \
--endpoints https://${HOST0}:2379 cluster-health
...
cluster is healthy
设置${ETCD_TAG}为ETCD的版本
3.2 第一个控制平面安装
3.2.1 添加外部etcd访问证书
在控制平面上执行以下命令将证书拷贝过来,这些证书只需要在第一个控制平面中存在。因为在部署时候指定了–upload-certs,这个参数可以将证书在控制平面中共享。
export ETCD_CA=10.57.26.7
mkdir -p /etc/kubernetes/pki/etcd/
scp root@${ETCD_CA}:/etc/kubernetes/pki/etcd/ca.crt /etc/kubernetes/pki/etcd/
scp root@${ETCD_CA}:/etc/kubernetes/pki/apiserver-etcd-client.crt /etc/kubernetes/pki/
scp root@${ETCD_CA}:/etc/kubernetes/pki/apiserver-etcd-client.key /etc/kubernetes/pki/
3.2.2 安装控制平面
创建kubeadm-config.yaml文件,可见与堆叠模式相比最大的不同是etcd使用external方式。
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
apiServer:
certSANs:
- "10.57.26.15"
controlPlaneEndpoint: "k8s-01:8443"
etcd:
external:
endpoints:
- https://10.57.26.7:2379
- https://10.57.26.8:2379
- https://10.57.26.26:2379
caFile: /etc/kubernetes/pki/etcd/ca.crt
certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt
keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
networking:
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
1)运行
kubeadm init --config kubeadm-config.yaml --upload-certs
2) 记录下join命令。
3)安装网络插件,这里使用flannel。
3.3 其他控制平面安装
1)保证第一个控制平面安装成功。
2)加入第一个控制平面安装成功输出的加入控制平面的命令,需要立即输入,key过2小时就将过期。
3.4 worker节点安装
1)保证控制节点安装成功。
2)加入第一个控制平面安装成功输出的加入工作节点的命令。
4 一些坑
4.1 本地镜像拷贝后不能pull和push
出现permission问题,需要更改selinux权限。 setenforce 0 以及selinux改权限
4.2 kubelet和docker的cgroup冲突问题
报错:failed to create kubelet: misconfiguration: kubelet cgroup driver: “cgroupfs” is different from docker cgroup driver: “systemd”
查看docker的cgroup docker info | grep Cgroup 修改kubelet的cgroup: 在/etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf配置文件中添加–cgroup-driver=systemd
4.3 环境清空
除了kubeadm reset以及iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X 还需要注意以下几点: 1) kubelet状态 查看systemctl status kubelet查看dropdown,删除不使用的配置,然后重启 systemctl daemon-reload&&systemctl restart kubelet 2) etcd删除 rm -rf /var/lib/etcd
5 一些收获
5.1 日志查看:
1:kubeadm的日志 kubeadm init –config kubeadm-config.yaml -v 256 后面加上-v 2:kubelet日志查看 journalctl -xefu kubelet 3:kubelet的配置信息可以通过 systemctl status kubelet查看
5.2 kubectl自动补全
yum install -y bash-completion
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)
6 参考
https://qingmu.io/2018/12/20/Deploy-a-highly-available-cluster-with-kubeadm/ https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/