常用组件命令
[toc]
1 hive
特点:不能更新,全量读
其中10000端口是hiveserver2的端口,从cdh中可以查看,如下:
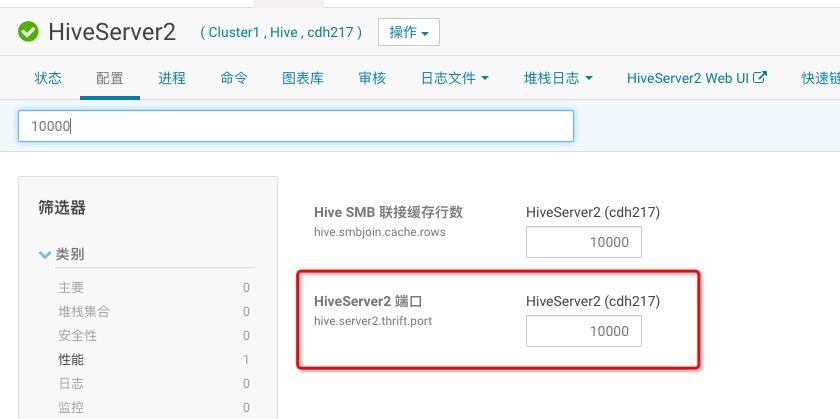
beeline -u jdbc:hive2://cdh217:10000
或者进到master里面,输入hive进去,操作和beeline一样
只能查text表,parquet表要到平台去查,因为要解压缩。
数据迁移: 导出 可以选格式:
INSERT OVERWRITE LOCAL DIRECTORY "/home/admin/data/data_20190601.txt" ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' select * from bigdata.nh_poc_detail_dt where ds='20190601'
动态分区导入:
LOAD DATA LOCAL INPATH '/home/admin/data/data_20190601.txt/' OVERWRITE INTO TABLE highroad.nh_poc_detail_dt partition (ds='20190601');
2 hbase
特点:更新快,只能rowkey读速度快 get ‘test’, “\x00\x00\x02\x08” get ‘test’, “\x00\x00\x02\x08”,‘cf1:dep_id’
3 hdfs
以hdfs://tdhdfs/user/hive/warehouse/testflink.db/kafka_to_hive5为例子
注意,若客户端要访问该地址的话,需要把tdhdfs添加进/etc/hosts中,tdhdfs是namenode地址,若配置ha的话写任意一个即可。
paquet文件可以通过spark直接读取。里面包含元信息。
hdfs追加数据
hadoop dfs -appendToFile <本地文件> <hdfs上文件>

distcp
4 zookeeper
5 kafka
安装
1 producer
netstat -pant | grep 9092可以查看,一般是zk的地址
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
2 consumer
有时候第一个命令没有,用第二个
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
或者
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
5.3 kafka-topics.sh
注:–zookeeper后参数从config/server.properties文件中zookeeper.connect参数获取
1 展示topic 展示topic名
bin/kafka-topics.sh --zookeeper localhost:2181 --list
2 描述topic 可以看到topic的分片数、leader、副本等信息
bin/kafka-topics.sh --zookeeper localhost:2181 --describe
3 创建topic
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic oob_syslog --partitions 1 --replication-factor 1
4 测试
./kafka-console-producer.sh --topic zhy_test --broker-list 10.57.239.111:9092
#导入文件
./kafka-console-producer.sh --topic zhy_test --broker-list 10.57.239.111:9092 < file
./kafka-console-consumer.sh --bootstrap-server 10.57.239.111:9092 --topic zhy_test --from-beginning
./kafka-console-consumer.sh --zookeeper 10.57.239.111:2181 --topic zhy_test --from-beginning
6 yarn
1 查看所有任务
yarn application -list
2 杀任务
yarn application -kill <id>
3 关闭交换分区
#查看内存剩余情况,若发现有Swap表示交换分区存在
free -h
#查看交换分区挂载盘
swapon -s
Filename Type Size Used Priority
/dev/dm-1 partition 33554428 0 -1
#关闭挂载分区
swapoff /dev/dm-1
#继续查看
swapon -s
#打开交换分区
swapon /dev/dm-1(需要换成自己的挂载分区)
6 redis
7 aerospike
环境: 测试:10.58.11.39:3000 大环境:10.57.30.214:3000,10.57.30.215:3000,10.57.30.216:3000
docker run -ti --name aerospike-asadm --rm aerospike/aerospike-tools asadm --host 10.57.30.214 --no-config-file
docker run -ti --name aerospike-aql --rm aerospike/aerospike-tools aql -h 10.57.30.214 --no-config-file
基础概念: namespace->database set->table bin->column
show相关:
#8 pheniox [root@cdh217 ~]$ /opt/modules/apache-phoenix-4.14.0-cdh5.14.2/bin/sqlline.py cdh217,cdh218,cdh219:2181
#9 presto 内存消耗型,小任务速度很快
公司测试环境
master:cdh218
slave:cdh217,cdh219
路径
/opt/modules/presto-server-0.218/bin
配置文件 1:config.properties 给个例子就能知道
master:
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8002
query.max-memory=5GB
query.max-memory-per-node=2GB
query.max-total-memory-per-node=5GB
exchange.min-error-duration=10.00m
exchange.client-threads=64
discovery-server.enabled=true
discovery.uri=http://cdh218:8002
slave:
coordinator=false
http-server.http.port=8002
query.max-memory=10GB
query.max-memory-per-node=2GB
exchange.min-error-duration=10.00m
exchange.client-threads=64
discovery.uri=http://cdh218:8002
2:node.properties
node.environment 表示集群名称,一个集群中的presto此参数必须一致
node.id 表示node的id名,每个集群中的presto需要设置不一样防止错乱
3:catalog/hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://cdh218:9083
hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml,/etc/hadoop/conf/mapred-site.xml,/etc/hadoop/conf/yarn-site.xml
hive.allow-drop-table=true
hive.allow-rename-table=true
4:mysql
connector.name=mysql
connection-url=jdbc:mysql://cdh217:3306
connection-user=root
connection-password=123456
命令
presto:ahnx> help
Supported commands:
QUIT
EXPLAIN [ ( option [, ...] ) ] <query>
options: FORMAT { TEXT | GRAPHVIZ }
TYPE { LOGICAL | DISTRIBUTED }
DESCRIBE <table>
SHOW COLUMNS FROM <table>
SHOW FUNCTIONS
SHOW CATALOGS [LIKE <pattern>]
SHOW SCHEMAS [FROM <catalog>] [LIKE <pattern>]
SHOW TABLES [FROM <schema>] [LIKE <pattern>]
USE [<catalog>.]<schema>
#10 druid
cdh218 coordinator router
cdh217 middleManager historical
cdh219 middleManager historical