Druid 介绍及相关框架对比
1 简介
Druid 是 MetaMarket 公司研发,专为海量数据集上的做高性能 OLAP (OnLine Analysis Processing)而设计的数据存储和分析系统,目前Druid已经在Apache基金会下孵化。Druid的主要特性: * 交互式查询( Interactive Query ): Druid 的低延迟数据摄取架构允许事件在它们创建后毫秒内查询,因为 Druid 的查询延时通过只读取和扫描有必要的元素被优化。Druid 是列式存储,查询时读取必要的数据,查询的响应是亚秒级响应。 * 高可用性( High Available ):Druid 使用 HDFS/S3 作为 Deep Storage,Segment 会在2个 Historical 节点上进行加载;摄取数据时也可以多副本摄取,保证数据可用性和容错性。 * 可伸缩( Horizontal Scalable ):Druid 部署架构都可以水平扩展,增加大量服务器来加快数据摄取,以及保证亚秒级的查询服务 * 并行处理( Parallel Processing ): Druid 可以在整个集群中并行处理查询 * 丰富的查询能力( Rich Query ):Druid支持 Scan、 TopN、 GroupBy、 Approximate 等查询,同时提供了2种查询方式:API 和 SQL
常见场景
- 点击流分析
- 网络流量分析
- 服务期指标存储
- 应用性能指标
- 数字化营销分析(广告)
- BI / OLAP
主要特点
- 列式存储
- 可伸缩分布式系统
- 大规模并行处理
- 实时和批量读取
- 自恢复,自平衡,操作简便
- 容错架构设计避免数据丢失
- 利用索引进行快速过滤
- 近似算法,去重统计/排名/直方图/分位点
- 在读入数据时进行聚合
主要特性:
- 为分析而设计——Druid是为OLAP工作流的探索性分析而构建。它支持各种filter、aggregator和查询类型,并为添加新功能提供了一个框架。用户已经利用Druid的基础设施开发了高级K查询和直方图功能。
- 交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内查询,因为Druid的查询延时通过只读取和扫描有必要的元素被优化。Aggregate和 filter没有坐等结果。
- 高可用性——Druid是用来支持需要一直在线的SaaS的实现。你的数据在系统更新时依然可用、可查询。规模的扩大和缩小不会造成数据丢失。
可伸缩——现有的Druid部署每天处理数十亿事件和TB级数据。Druid被设计成PB级别。 Druid对于需要实时单一、海量数据流摄取产品非常适合。特别是如果你面向无停机操作时,如果你对查询查询的灵活性和原始数据访问要求,高于对速度和无停机操作,Druid可能不是正确的解决方案。在谈到查询速度时候,很有必要澄清“快速”的意思是:Druid是完全有可能在6TB的数据集上实现秒级查询。当业务中出现以下情况时,Druid是一个很好的技术方案选择:
需要交互式聚合和快速探究大量数据时;
需要实时查询分析时;
具有大量数据时,如每天数亿事件的新增、每天数10T数据的增加;
对数据尤其是大数据进行实时分析时;
需要一个高可用、高容错、高性能数据库时。
能做什么
- 数据频繁插入,更新操作较少的场景
- 大部分查询都是聚合和报告查询(group by),部分搜索和扫描查询
- 查询延迟定位为100毫秒到几秒钟
- 数据需要包含一个时间维度(Druid会对时间维度进行相关的优化)
- 每个查询只能访问一个大的分布式表
- 有高基数数据列(例如URL,用户ID),需要对它们进行快速计数和排名。
- 从Kafka,HDFS,文件或对象存储(如Amazon S3)加载数据。
不能做什么
- 需要使用主键对现有记录进行低延迟更新。Druid支持流式插入,但不支持流式更新(可以使用后台批处理作业进行更新)
- 需要一个离线的报表系统,同时对查询延时并不是很在意
- 大表与大表的关联操作
2 为什么需要 Druid
- 大数据平台目前缺少实时数据聚合查询的能力
- 可与 spark 相互补充,在 OLAP 上减少资源消耗,提高计算资源利用率和查询效率
- BI 使用 presto 扫描查询的方式负载较高
3 架构
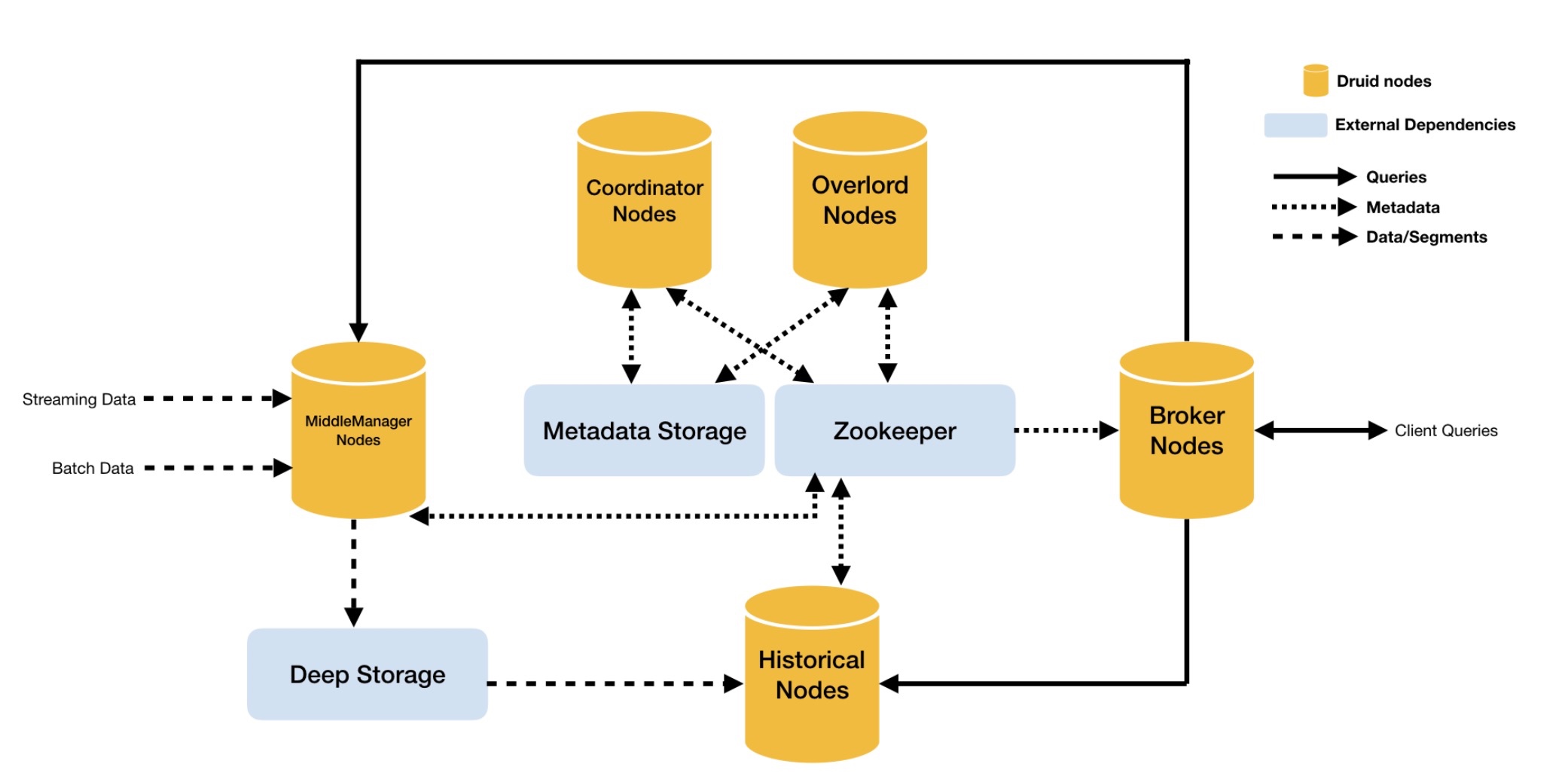
3.1 节点
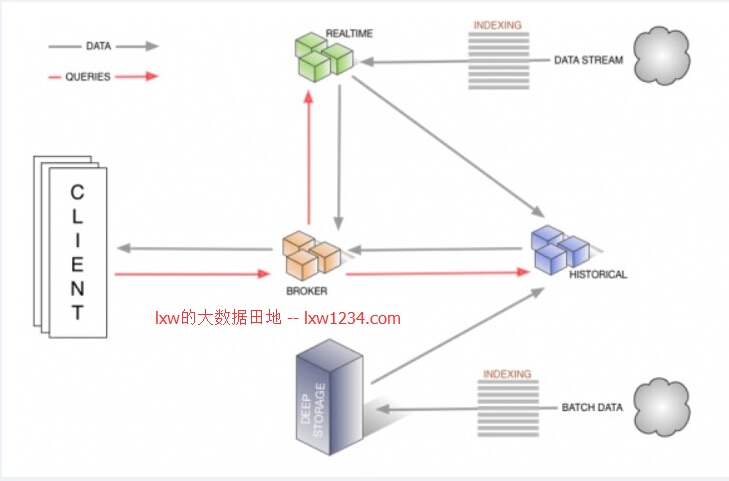
Historical Node:是对“historical”数据(非实时)进行处理存储和查询的地方。Historical节点响应从Broker节点发来的查询,并将结果返回给broker节点。它们在Zookeeper的管理下提供服务,并使用Zookeeper监视信号加载或删除新数据段。
Real-time Node:实时摄取数据,它们负责监听输入数据流并让其在内部的Druid系统立即获取,Realtime节点同样只响应broker节点的查询请求,返回查询结果到broker节点。旧数据会被从Realtime节点转存至Historical节点。
Coordinator Node:监控Historical节点组,以确保数据可用、可复制,并且在一般的“最佳”配置。它们通过从MySQL读取数据段的元数据信息,来决定哪些数据段应该在集群中被加载,使用Zookeeper来确定哪个Historical节点存在,并且创建Zookeeper条目告诉Historical节点加载和删除新数据段。
Broker Node:接收来自外部客户端的查询,并将这些查询转发到Realtime和Historical节点。当Broker节点收到结果,它们将合并这些结果并将它们返回给调用者。由于了解拓扑,Broker节点使用Zookeeper来确定哪些Realtime和Historical节点的存在。
Overlord Node (Indexing Service):Overlord会形成一个加载批处理和实时数据到系统中的集群,同时会对存储在系统中的数据变更(也称为索引服务)做出响应。另外,还包含了Middle Manager和Peons,一个Peon负责执行单个task,而Middle Manager负责管理这些Peons。
一个Druid集群有各种类型的节点(Node)组成,每个节点都可以很好的处理一些的事情,这些节点包括对非实时数据进行处理存储和查询的Historical节点、实时摄取数据、监听输入数据流的Realtime节、监控Historical节点的Coordinator节点、接收来自外部客户端的查询和将查询转发到Realtime和Historical节点的Broker节点、负责索引服务的Indexer节点。
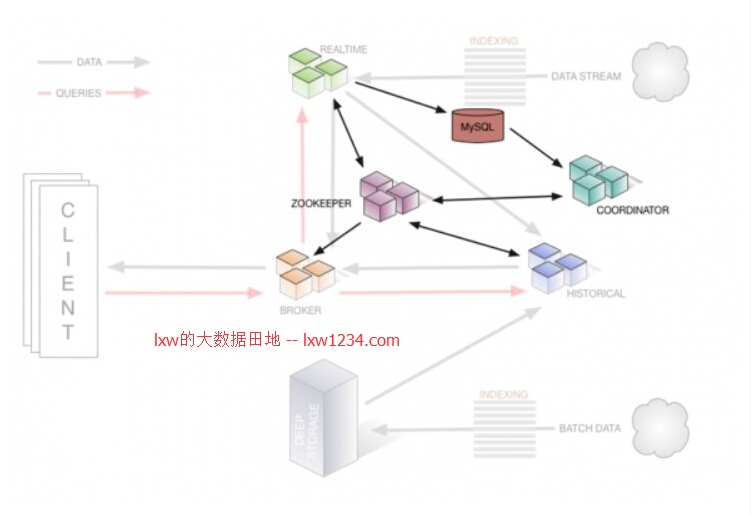
ZooKeeper:为集群服务发现和维持当前的数据拓扑而服务;
MySQL:用来维持系统服务所需的数据段的元数据;
Deep Storage:保存“冷数据”,可以使用HDFS。
3.2 Segments
Druid 把它的索引存储到一个Segment文件中,Segment文件是通过时间来分割的。
Segment数据结构
对于摄入到Druid的数据的列,主要分三种类型,时间列,指标列和维度列。如下图
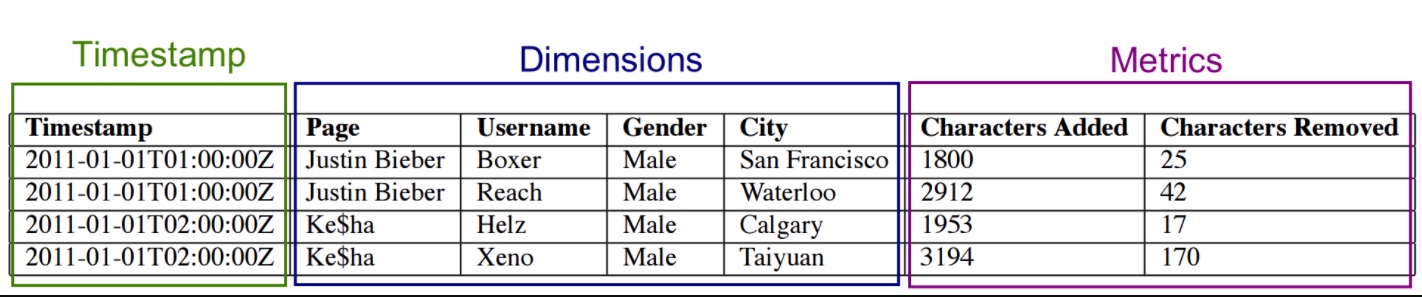
对于时间列和指标列处理比较简单,直接用LZ4压缩存起来就ok,一旦查询知道去找哪几行,只需要将它们解压,然后用相应的操作符来操作它们就可以了。维度列就没那么简单了,因为它们需要被过滤和聚合,因此每个维度需要下面三个数据结构。
一个map,Key是维度的值,值是一个整型的id 一个存储列的值得列表,用1中的map编码的list 对于列中的每个值对应一个bitmap,这个bitmap用来指示哪些行包含这个值。 对于上图的Page列,它的存储是这样的
字典 { “Justin BIeber”: 0, “Ke$ha”: 1 }
值的列表 [0, 0, 1, 1]
bitMap value=“Justin Bieber”: [1, 1, 0, 0] value=“Ke$ha”: [0, 0, 1, 1]
3.3 索引服务
索引服务是一个高可用的,分布式的服务来运行索引相关的Task。索引服务会创建或者销毁Segment。索引服务是一个Master/Slave架构。索引服务是三个组件的集合
- peon组件用来跑索引任务。
- Middle Manager组件用来管理peons
- Overlord向MiddleManager分发任务。
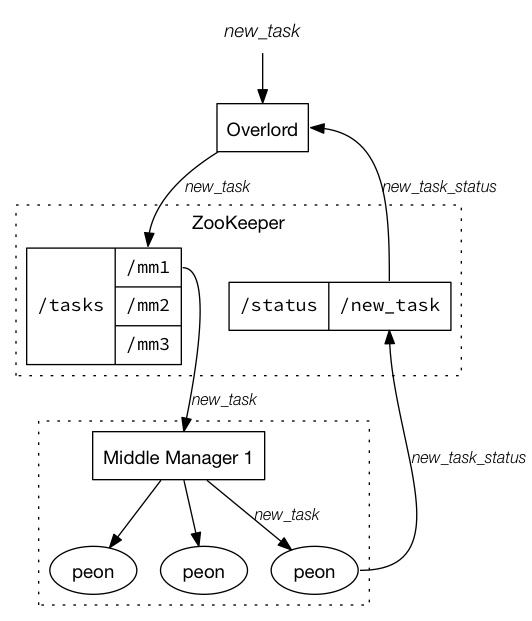
Overlord节点负责接受任务,协调任务分发,创建锁,和返回状态给调用者。Overlord节点可以以本地模式或者远程模式运行。本地模式会直接创建Peon,远程模式会通过Middle Manager创建任务。
3.4 实时节点
实时节点提供实时索引服务,通过实时节点索引的数据立即可查。实时节点会周期性的构建Segment,并且把这些Segment推到历史节点并修改元数据。
4 OLAP 选型对比
Druid vs 数据检索引擎 (ES) ES可以存储结构化和非结构化数据,同时具备明细查询和聚合查询能力,由于其自身是一个数据检索引擎,其索引类型并不是针对聚合分析设计的,所以聚合查询方面开销较大;其次,ES不但要保存所有的原始数据,还需要生成较多的索引,所以存储空间开销会更大,数据的写入效率方面会比 Druid 差一些。
与ES相比,只能处理结构化数据,因为它必须预定义Schema;其次,Druid会对数据进行预聚合以减少存储空间,同时对数据写入和聚合进行优化。但是,由于进行了预聚合,所以Druid抛弃掉了原始数据,导致其缺少原始明细数据查询能力。如果业务方有需求,可以关闭预聚合,但会丧失Druid的优势。
- Druid在导入过程会对原始数据进行 roll up,而ES会保存原始数据
- Druid专注于OLAP,针对数据导入以及快速聚合操作做了优化
- Druid只能处理结构化数据,不支持全文检索
Druid vs 预计算+KV (Kylin) 预计算 + kv存储方式 ,KV存储需要通过预计算实现聚合,可以认为Key涵盖了查询参数,而值就是查询结果,由于直接从KV存储进行查询,所以速度非常快。缺点是因为需要在预计算中处理预设的聚合逻辑,所以损失了查询灵活性,复杂场景下的预计算过程可能会非常耗时,而且面临数据过于膨胀的情况;由于只有前缀拼配一种索引方式,所以在大数据量的复杂过滤条件下,性能下降明显;且缺少聚合下推能力。
Druid 采用列存储,倒排和 bitmap 索引提高查询速度,光从查询上速度肯定不如预计算+KV存储快,但是由于使用内存增量索引,增量预聚合的模式,写入即可查,无需等待预计算生成Cube,所以实时性更强;其次,Druid可针对任意维度组合过滤、聚合,查询更加灵活;最后,Scatter & Gather模式支持一定的聚合下推。
Kylin 优势:
- 预计算比 Druid 更强大
- SQL支持更加完善
- 对星型模型的支持更好
- 支持大表 Join
查询命中后效率极高 Kylin 劣势:
支持通过 kafka 构建 cube,但是有一定延时(分钟级别),不适合实时监控和告警 需要提前预算所有可能的维度组合,查询缺少灵活性
Kylin 通过提前定义 cube 进行预计算和定期任务,将结果存在 Hbase 中,大部分查询可以直接通过 Hbase 获取结果,查询缺少灵活性,不支持实时查询和自定义查询,更适合查询较为固定,离线报表和实时性要求并不是特别高的 OLAP 场景。
Druid vs K/V Stores (Hbase / Cassandra) Druid 为扫描和聚合操作做了大量优化,且支持任意深度的数据上钻操作。
K/V数据库想做到相同的事情必须在记录上进行 Range Scan,然后以事件维度作为键,度量作为值,聚合操作则需要对数据进行范围扫描来实现,KV存储模型有一个特点,只能根据前缀进行Range Scan,而不能对任意维度上进行索引过滤(不考虑二级索引),而且做不到精准扫描,因此不能通过谓语减少扫描的数据量,当扫描的行数很大时,性能将会急剧的下降,同时实现数据本地性较为困难因为无法把聚合操作下推到存储层。
以OpenTSDB为例,OpenTSDB是基于HBase的时序数据库。它的优势在于查询速度快、扩展性好,且schemaless。然而,它也有一些缺点:查询的维度组合数量需要提前确定好,即通过存储中的tag组合来确定,因此缺乏了灵活性;数据冗余度大;基于HBase,对于运维人员能力要求较高。
从数据探索的角度来说,Druid 支持任意列的 ad-hoc 查询而不需要提前计算,同时列存储的特性让其列扫描速度也非常快,这可以提高聚合操作的性能。
Druid vs SQL-on-Hadoop (Impala/Drill/Spark SQL/Presto) SQL支持强大,且无冗余数据,不需要预处理。缺点是因为其直接通过计算引擎对Hadoop上的文件进行操作,所以响应速度较慢且QPS相对较低。
- 查询,Druid采用 Scatter/Gather 模式,SQL-on-Hadoop大多采用MPP方式,把执行计划分布在多个节点去执行,节点之间网络通讯以及序列化/反序列化(Serde)都会带来一定的开销。
- 数据导入,Druid支持实时导入,SQL-on-Hadoop 一般将数据存储在Hdfs上,Hdfs的写入速度有可能成为瓶颈
- Druid目前 SQL 支持有限。
Druid vs Pinot 两者定位和使用场景非常相近,Pinot 同样采用 lambda 架构,支持从 kafka 准实时摄入数据及Hadoop批量摄入数据。
Pinot 不同字段支持多种自定义的索引,而 druid 则是固定 Bitmap。 PQL 语法更接近 SQL,设计更为规范,不过由于开源时间较短,相较于 Druid 目前使用案例及资料太少。